

ADHDにはコンサータおよびインチュニブならびにストラテラ等の有効な治療薬が存在しますが、これらの処方には医師による診断が必要です。現在ADHDの診断はDSM-5という基準に従って実施されていますが、その解釈は医師よって異なり、誤診による不適切な治療が後を絶ちません。治療薬の正しい処方のため、医師の主観によらない客観的な診断方法の確立が急務となっています。
ADHDは遺伝的に決まる側面がある一方、発症には環境要因も強く関わっています。そこで、健常人とADHD患者の全血トランスクリプトームのデータを比較し、環境要因も加味したバイオマーカーを調べる研究が報告されています。
本研究では上記の研究にて公開されているデータに基づき、血液トランスクリプトームからADHDか判定する機械学習モデルを作成します。特に本記事では、ランダムフォレストによる予測モデル構築について説明します。
0. はじめに
本記事は、以下の記事の続きになります。

1. データセットの用意
import time
import pickle
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import pearsonr
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
import umap
from scipy.sparse.csgraph import connected_components
import scipy.stats as st
from scipy.stats import mannwhitneyu
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import GridSearchCV
import warnings
warnings.filterwarnings('ignore')
X = df_ttest.iloc[:, :-1]
y = df_ttest.iloc[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y)2. 学習
model = RandomForestClassifier() model.fit(X_train, y_train) test = model.predict(X_test)
3. 精度
score = accuracy_score(y_test, test) score
0.81254. ROCカーブ
prob = model.predict_proba(X_test)
fpr_all, tpr_all, thresholds_all = roc_curve(y_test, prob[:,1], drop_intermediate=False)
plt.plot(fpr_all, tpr_all, marker='o')
plt.xlabel('FPR: False positive rate')
plt.ylabel('TPR: True positive rate')
plt.grid()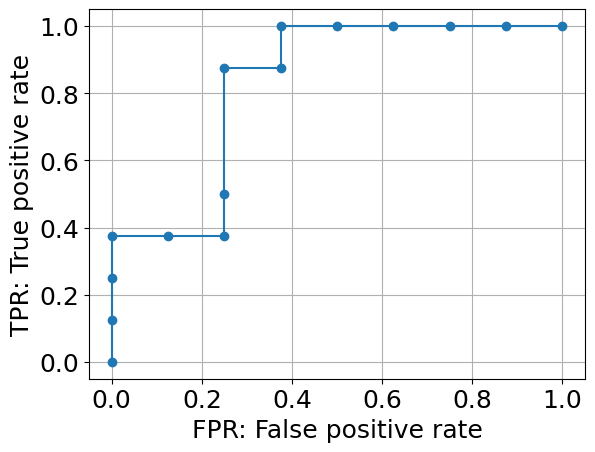
5. AUC
roc_auc_score(y_test, prob[:,1])
0.8281256. まとめ
題材にもよりますが、AUCは0.7を超えれば十分に良いモデルと言われます。
今回のランダムフォレストによって作成したモデルで十分にADHDを判定できるモデルができたと言えます。
あとは、交差検証やハイパーパラメータ、訓練データ・テストデータを入れ替えた再現性確認をすれば良さそうです。


コメント